Your Policy Regulariser is Secretly an Adversary
By Rob Brekelmans, Tim Genewein, Jordi Grau-Moya, Grégoire Delétang, Markus Kunesch, Shane Legg, Pedro A. Ortega
Full paper, published in TMLR, here: arxiv.org/abs/2203.12592, OpenReview
TL;DR: Policy regularisation can be interpreted as learning a strategy in the face of an imagined adversary; a decision-making principle which leads to robust policies. In our recent paper, we analyse this adversary and the generalisation guarantees we get from such a policy.
Playing against an imagined adversary leads to robust behaviour
The standard model for sequential decision-making under uncertainty is the Markov decision process (MDP). It assumes that actions are under control of the agent, whereas outcomes produced by the environment are random. MDPs are central to reinforcement learning (RL), where transition-probabilities and/or rewards are learned through interaction with the environment. Optimal policies for MDPs select the action that maximises future expected returns in each state, where the expectation is taken over the uncertain outcomes. This, famously, leads to deterministic policies which are brittle — they “put all eggs in one basket”. If we use such a policy in a situation where the transition dynamics or the rewards are different from the training environment, it will often generalise poorly.
For instance, we might learn a reward model from human preferences and then train a policy to maximise learned rewards. We then deploy the trained policy. Because of limited data (human queries) our learned reward function can easily differ from the reward function in the deployed environment. Standard RL policies have no robustness against such changes and can easily perform poorly in this setting. Instead, we would like to take into account during training that we have some uncertainty about the reward function in the deployed environment. We want to train a policy that works well, even in the worst-case given our uncertainty. To achieve this, we model the environment to not be simply random, but being (partly) controlled by an adversary that tries to anticipate our agent’s behaviour and pick the worst-case outcomes accordingly.

Implementing the adversary
We play the following game: the agent picks a policy, and after that, a hypothetical adversary gets to see this policy and change the rewards associated with each transition — the adversary gets to pick the worst-case reward-function perturbation from a set of hypothetical perturbations. When selecting a policy, our agent needs to anticipate the imagined adversary’s reward perturbations and use a policy that hedges against these perturbations in advance. The resulting fixed policy is robust against any of the anticipated perturbations. If, for instance, the reward function changes between training and deployment in a way that is covered by the possible perturbations of the imagined adversary, there is no need to adapt the policy after deployment; the deployed robust policy has already taken into account such perturbations in advance.
Optimisation in the face of this kind of adversary puts us in a game-theoretic setting: the agent is trying to maximise rewards while the adversary is trying to minimise them (a mini-max game). The adversary introduces “adaptive uncertainty”: the agent cannot simply take the expectation over this uncertainty and act accordingly because the adversary’s actions depend on the agent’s choices. Optimal strategies of the agent in this setting are robust stochastic policies. This robustness is well known via the indifference principle in game theory: acting optimally means using a strategy such that the agent becomes indifferent to the opponent’s choices.
While the idea of the imagined adversary seems neat for obtaining robust policies, the question that remains is how to perform the game-theoretic optimisation involved? In our recent paper, we show that when the adversary is of a particular kind, we do not need to worry about this question. Using mathematical tools from convex duality, it can be shown that standard RL with policy regularisation corresponds exactly to the mini-max game against an imagined adversary. The policy that solves one formulation also solves the dual version optimally. There is no need to actually implement the adversary, or feed adversarially perturbed rewards to the agent. We can thus interpret policy-regularised RL from this adversarial viewpoint and explain why and how policy regularisation leads to robust policies.
Using convex duality to characterise the imagined adversary
The goal of our paper is to show how policy regularisation is equivalent to optimisation under a particular adversary, and to study that adversary. Using convex duality, it turns out that the adversary we are dealing with, in case of policy regularised RL, has the following properties:
- The adversary applies an additive perturbation to the reward function:
r’(s, a) = r(s, a)- Δr(s, a) - It pays a cost for modifying the agent’s rewards, but only has a limited budget. The cost function depends on the mathematical form of the policy regulariser — we investigate KL- and alpha-divergence regularisation. The budget is related to the regulariser strength.
- The adversary applies a perturbation to all actions simultaneously (it knows the agent’s distribution over actions, but not which action the agent will sample). This generally leads to reducing rewards for high-probability actions and increasing rewards for low-probability actions.
Using the dual formulation of the regulariser as an adversary, we can compute worst-case perturbations (Δr⁎). Consider the following example to get an intuition for a single decision step:
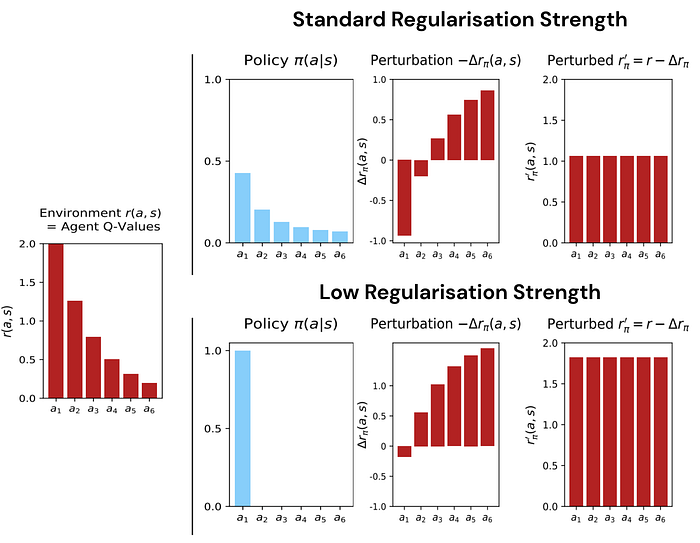
The virtually unregularised policy shown above (second column, bottom) almost deterministically selects the highest-reward action; decreasing the reward for this action is very “costly” for the adversary, but even small decreases will have an impact on the expected rewards. Conversely, the reward perturbations for low-probability actions need to be much larger to have an impact (and can be interpreted as being “cheaper” for the adversary). Solutions to the mini-max game between agent and adversary are characterised by indifference, as shown in the fourth column. Under the (optimally) perturbed reward function, the agent has no incentive to change its policy to make any of the actions more or less likely since they all yield the same perturbed reward — the optimal agent receives equal value for each of its actions after accounting for the adversary’s optimal strategy. (Note that this indifference does not mean that the agent chooses actions with uniform probabilities.)
Increasing the regularisation strength (top row) corresponds to a stronger adversary with an increased budget. This results in a lower value of the indifference point (fourth column y-axis, top, compared to bottom) and a more stochastic policy (second column, top, compared to bottom).
Generalisation guarantee
The convex-dual formulation also allows us to characterise the full set of perturbations available to the adversary (the “feasible set” in the paper; we have already seen the worst-case perturbation in the illustration above). This allows us to give a quantitative generalisation guarantee:
Generalisation guarantee (robustness): for any perturbation in the feasible set the (fixed) policy is guaranteed to achieve an expected perturbed reward, which is greater than or equal to the regularised objective (expected cumulative discounted reward minus the regulariser term).
The regulariser strength corresponds to the assumed “powerfulness” of the adversary, and the cost that the adversary has to pay is related to either a KL- or an alpha-divergence with respect to some base-policy. If the base policy is uniform and we use the KL divergence, we recover the widely used entropy-regularised RL. We can compute and visualise the (feasible) set of perturbations that our policy is guaranteed to be robust against for high, medium and low regularisation, shown here:
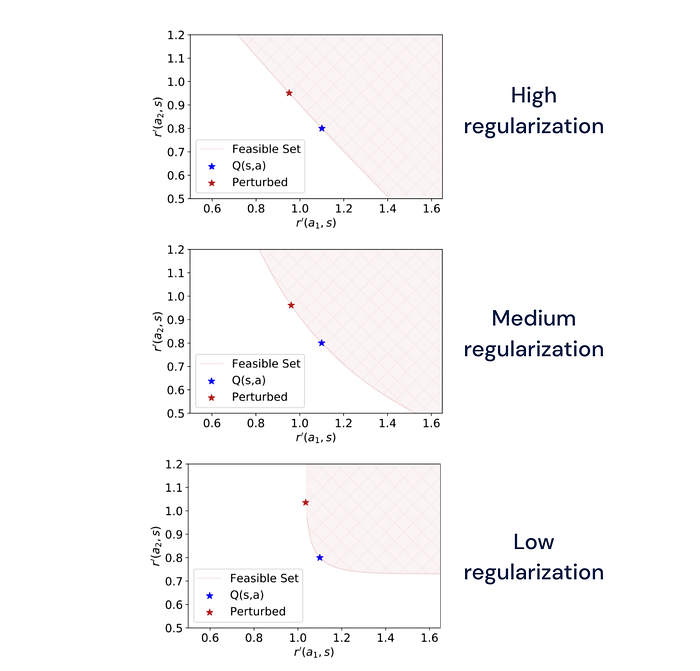
One insight from the formal analysis is that the adversary that corresponds to policy regularisation behaves such that decreases in rewards for some actions are compensated for by increases in rewards for other actions in a very particular way. This is different, e.g. from a more intuitive “adversarial attack” on the reward function that only reduces rewards given a certain magnitude.
The second observation that we want to highlight is that increased robustness does not come for free: the agent gives up some payoff for the sake of robustness. The policy becomes increasingly stochastic with increased regulariser strength, meaning that it does not achieve maximally possible expected rewards under the unperturbed reward function. This is a reminder that choosing a regulariser and its weighting term reflects implicit assumptions about the situations (and perturbations) that the policy will be faced with.
Related work and further reading
In our current work, we investigate robustness to reward perturbations. We focus on describing KL- or alpha-divergence regularisers in terms of imagined adversaries. It is also possible to choose adversaries that get to perturb the transition probabilities instead, and/or derive regularizers from desired robust sets (Eysenbach 2021, Derman 2021).
- Read our paper for all technical details and derivations. All statements from the blog post are made formal and precise (including the generalisation guarantee). We also give more background on convex duality and an example of a 2D, sequential grid-world task. The work is published in TMLR.
- To build intuition and understanding via the single-step case, see Pedro Ortega’s paper, which provides a derivation of the adversarial interpretation and a number of instructive examples.
- Esther Derman’s (2021) recent paper derives practical iterative algorithms to enforce robustness to both reward perturbations (through policy regularization) and changes in environment dynamics (through value regularization). Their approach derives a regularization function from a specified robust set (such as a p-norm ball), but can also recover KL or α-divergence regularization with slight differences to our analysis.
Changelog
8 Aug. 2022: Updated with TMLR publication information, updated single step example figure to match final version of paper, updated discussion of related work to give more details to relation to Derman 2021.
