Steering Gemini using BIDPO vectors
By Alex Turner and Mark Kurzeja
A while back, we explored the “BIDPO” method for training steering vectors. In Gemini 1.5v1 Flash and Pro, BIDPO steering vectors boosted TruthfulQA scores by >10% while mostly retaining capabilities. When we updated to Gemini 1.5v2, prompt-based steering baselines became significantly stronger. BIDPO did not beat the stronger baselines, ending the project.
Introduction
We want to elicit the full knowledge and capabilities of a model — to understand what a model “really” knows (Christiano et al., 2021; Mallen et al., 2023; Burns et al., 2022). By doing so, our models become statistically more reliable and we have greater reason to trust any given output. A more “honest” and factual model provides better AI feedback (Bai et al., 2022), leading to better alignment data and stronger overall supervision of future model training (Burns et al., 2023). A more factual model produces outputs which overall require less scrutiny (which also helps AI-assisted human raters).
Towards this goal, we investigated three hypotheses:
- Steering can boost performance in an absolute sense. Prior work (Panickssery et al. 2023; Li et al., 2023; Liu et al. 2023) suggested that steering vectors are not only able to boost performance, but that they boost performance above and beyond the gains provided by supervised finetuning and few-shot prompting. If that scaled to Gemini, steering vectors would become a valuable addition to safety post-training.
- Steering vectors are more parameter- and sample-efficient interventions. Even a rank-1 LORA can take substantial memory (namely, O(2 × n_layers × d_model})) and hundreds of examples. Results like (Li et al., 2023) suggest that steering can work with a few dozen labeled examples, and perhaps without taking any gradients at all.
- Steering can improve response velocity for losses. A fast steering intervention can be iterated and evaluated quickly, whereas finetuning might require a lot more care and compute. This is especially useful for safety. For example, it could be used as part of a rapid response system for novel jailbreaks.
We remained wary of several potential obstacles, including performance degradation (Stickland et al., 2024).
Initial positive results
Using Gemini Flash 1.5v1, we observed positive signals for vectors trained on TruthfulQA using BIDPO — a variant of DPO. Basically, we trained a vector to maximize the logit difference between a correct and incorrect multiple-choice answer. We used 256 TruthfulQA training points in order to produce the BIDPO vectors. We hoped that a TruthfulQA vector could improve general model factuality.
Dataset boosts
- BIDPO achieved a 16% boost on TruthfulQA multiple-choice validation. Multi-shot prompting achieved a 4% boost using the same 256 training questions (74.6% → 78.8%). LORA achieved a 17.8% boost using the same data.However, by combining the LORA with the already-trained BIDPO steering vector, we achieved a 19% boost (to 93.3%). However, the standard error was 1.7% and the boost over LORA was just 1.5% — weakening this result.
- The “truthfulness” boost seemed to generalize beyond TruthfulQA. HaluEval evaluates whether the model can recognize when a proposed answer is made-up. On two splits of HaluEval, the vector increased performance (in one case, from 25% to 56%).
- We found “Pareto” BIDPO vectors which achieved ~11% boosts while preserving performance on a range of multiple-choice capabilities datasets. One kind of model sycophancy improved by 5% (+4sd) due to a Pareto vector, while other sycophancy datasets had unchanged performance.
We achieved similar positive results on Gemini Pro 1.5v1 (instead of Flash).
Assessing long-form abilities
We tested:
- Chain-of-thought capability on MMLU and TruthfulQA multiple-choice. The vectors boosted TruthfulQA slightly but also degraded MMLU. We concluded that conditional activation steering would be required for production usage.
- Free-form responses to TruthfulQA questions (omitting the answer options). Gemini 1.5 Pro compared the responses in a head-to-head between the steered and unsteered Flash models. The steered Flash won 56.6% of the time, which had a one-tailed z-score of +2.1 and so was statistically significant (p<.05).
Other points of strength
- An internal client strongly preferred contrastively steered models to system prompted models for their use case.
- A single BIDPO update on a single TruthfulQA datapoint produced a >10% boost on TruthfulQA validation, and several seeds produced a 7% boost. We were excited by the possibility of extreme sample- and parameter-efficiency.

Negative results in Gemini 1.5v2
Gemini 1.5v2 constituted a moderate upgrade to overall Gemini capabilities. When 1.5v2 landed, nearly all of our positive signs flipped to negative. Gemini Pro 1.5v2 had higher unsteered TruthfulQA performance, while Flash 1.5v2 did not. However, both models seemed significantly better at following instructions and learning from many-shot examples.
Dataset boosts
- BIDPO achieved 92.6% on TruthfulQA, a 17.6% boost over the unsteered score of 75%. 256-shot prompting achieved 95%, meaning we no longer beat the obvious baseline of multi-shot prompting. LORA also achieved at least 95%.
- We tried combining BIDPO + LORA, but this no longer boosted performance.
- The HaluEval “generalization” result was caused by a data labeling error which flipped the correct answer for each question. At best, the TruthfulQA vectors preserved HaluEval performance.
- The “Pareto” vectors (derived from 256 TruthfulQA examples) had somewhat worse transfer than 32-shot prompting.
Assessing long-form abilities
- BIDPO vectors no longer boosted freeform TruthfulQA performance. In fact, they slightly degraded performance. We verified this result by manually rating each pair of responses (using blinding).
Previous points of strength
- Using a new steering vector for a 1.5v2 model, the aforementioned internal client now strongly preferred the system-prompted outputs.
- We were no longer able to produce statistically significant gains using a single datapoint. Furthermore, LORA proved surprisingly sample-efficient, achieving a 13% boost using just 16 datapoints.
Furthermore, we realized that TruthfulQA and HaluEval are low-quality datasets — at least when used for multiple-choice Q/A. This realization further questioned the validity of boosts on TruthfulQA, as now it was possible that the BIDPO vector simply taught the model to look for simple patterns in TruthfulQA.
Lessons learned
In hindsight, Gemini 1.5v1 was less responsive to in-context learning on a set of examples. If we had realized this overhang, we may have saved lots of time.
Carefully manually inspect every dataset. Make sure to take a representative sample. Error prevented: trusting TruthfulQA (multiple choice) and HaluEval.
Manually inspect data questions and their metadata. We checked e.g. “does the ‘correct’ answer make sense?”, but not consistently. Error prevented: for a while, our HaluEval labels were reversed.
Test long-form generations sooner. Error prevented: none, but we would have noticed some of the negative results more quickly.
Implement regression and integration testing early. We relied on point-in-time evaluations to sanity check our infrastructure. Error prevented: Several regressions in the stack under us, which cost several SWE days and partially compromised results.
Ensure datasets have statistical power to make progress. For example, TruthfulQA validation only had 256 points. Error prevented: noisy evaluations.
Generate and analyze data separately in case the generation pipeline changes or breaks in the future. Error prevented: Inability to plot complete 1.5v1 statistics on e.g. multi-shot prompting.
Conclusion
BIDPO seems effective and sample-efficient but does not currently exceed more standard baselines. It’s hard to draw firm conclusions about BIDPO because TruthfulQA might not be measuring truthfulness / factuality. However, we remain excited about DPO-driven Conditional Activation Steering, which has additional advantages — particularly for targeted loss mitigation.
Thanks to David Elson, Rohin Shah, Dave Orr, and others for feedback. Arthur Conmy and the GDM language model interpretability team helped with infrastructure.
Appendix: Method
BIDPO training
While contrastive activation addition (Panickssery et al., 2023) did well on Gemini 1.0 models, initial evidence suggested that it did not transfer to Gemini 1.5 models. Instead, we used the recent BIDPO algorithm (Cao et al., 2024) to train a “virtual bias term” which increases attribute X when added and decreases attribute X when subtracted. We call these trained bias terms “steering vectors” (which can be applied whether or not the original architecture contained bias terms).

A training dataset is broken up into batches of size eight in our experiments. For each batch:
- The BIDPO loss is computed for the batch,
- The gradient is computed with respect to the steering vector, and
- The vector is updated using the AdamW optimizer (Loshchilov & Hutter, 2019).
This process continues until the entire dataset is exhausted. We may repeat this process for multiple epochs.
When evaluating BIDPO vectors mid-training, we “renormalized” them to have a norm equal to about 5% of the average norm of the residual stream at that part of the forward pass.
LORA training
Our LORAs are trained with rank 1, a learning rate of .0001, and a batch size of 16. We evaluate the trained LORAs every 50 steps and evaluate validation accuracy on the checkpoint with lowest validation loss.
The LORA modifies every layer of the transformer. With a rank of n_rank, a LORA has 2 × d_model × n_layers parameters. Since BIDPO only trains a bias term of size d_model, a rank-(n_rank) LORA uses 2 × n_rank × n_layers times the parameter count. As it is not uncommon to use e.g. n_rank = 128 LORAs, on e.g. a 50-layer model, a LORA may well require 12,800 times as many parameters as a BIDPO steering vector.
Experiment design
We split TruthfulQA (Lin et al., 2021) into 256 training, 256 validation, and 304 test data points. TruthfulQA is intended to measure how often a model promotes misconceptions or falsehoods. We use TruthfulQA’s MC1 variant, containing multiple choice questions with a single correct answer.
To assess the BIDPO intervention, we quantify its impacts on alignment and on capabilities. Unless otherwise mentioned, all experiments are zero-shot multiple choice.
Alignment benchmarks. We measure in-distribution generalization by measuring the performance on the TruthfulQA test set. We measure out-of-distribution “truthfulness” generalization by considering the Natural Questions dataset (Kwiatkowski et al., 2019) (in line with prior work (Li et al., 2023; Chen et al., 2024; Zhang et al., 2024)). To produce incorrect choices for Natural Questions (which only contains correct answers), we had Gemini Pro 1.5v1 produce an answer which looked correct but wasn’t.
We also measured impact on SycophancyEval (Sharma et al., 2023), testing how often the model tailors its response to the user’s opinion. We consider generalization to HaluEval (Li et al., 2023) and to (Panickssery et al., 2023)’s hallucination dataset, both of which aim to measure hallucination rates.
Capabilities benchmarks. We test general performance and reasoning using MMLU (Hendrycks et al., 2020), Winogrande (Sakaguchi et al., 2019), BoolQ (Clark et al., 2019), PIQA (Bisk et al., 2020), ARC (Clark et al., 2018), and HellaSwag (Zellers et al., 2019).
Experiment results
We thoroughly optimized hyperparameters for BIDPO. The most important hyperparameters turned out to be the steering vector magnitude (and sign) and the learning rate.
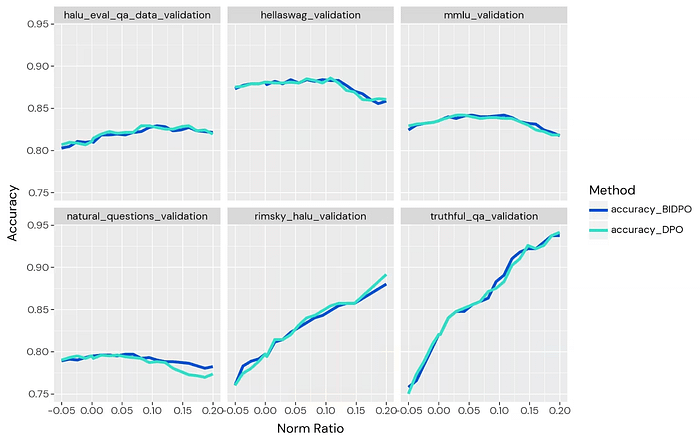
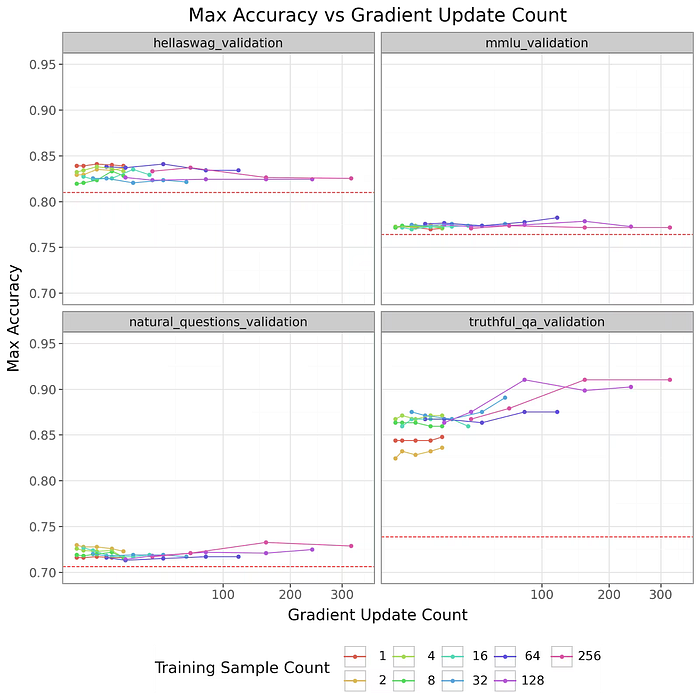
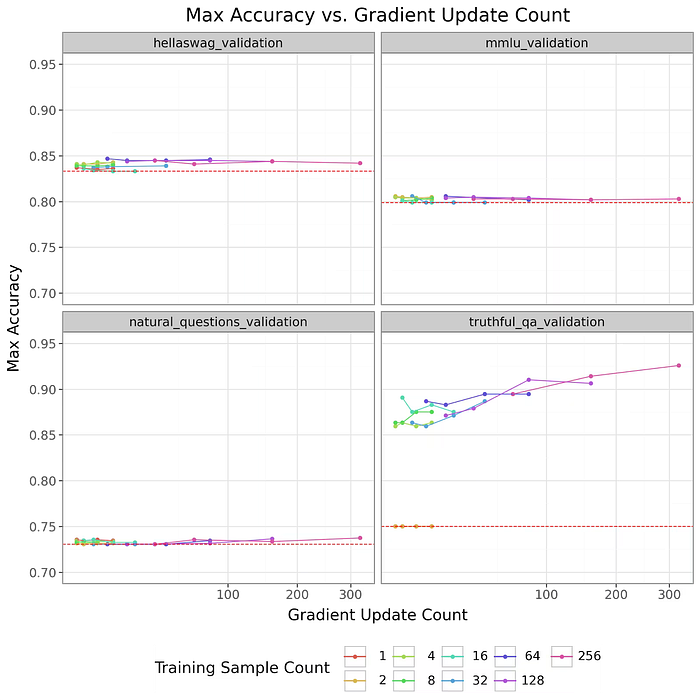
Data efficiency
We trained BIDPO vectors on a range of datasets and measured in-distribution generalization (validation performance). Using optimized hyperparameters, we took subsets of the 256-element training distribution. To reduce variance, the larger training sets are strict supersets of the smaller training sets.
Gemini 1.5v1
Gemini 1.5v2
Multi-shot prompting
We did not record comprehensive 1.5v1 data on multi-shot prompting generalization. However, using 256-shot TruthfulQA on Gemini Flash 1.5v1 caused a mere 4% boost on TruthfulQA.
In contrast, on Gemini Pro 1.5v2, multishot prompting was extremely effective:

Prior work
Activation engineering
(Mini et al., 2023) controlled a maze-solving deep convolutional network by adding and subtracting activation vectors. In follow-on work, (Turner et al., 2023) shifted the sentiment and topic of GPT-2 by adding in activation vectors (“steering vectors”) to steer the model’s outputs. Both works demonstrated effective activation engineering: the inference-time modification of activations to steer a network’s outputs. (Panickssery et al., 2023) explored “contrastive activation addition” (CAA) through contrasting the average residual stream difference between desired and undesired answers. CAA vectors effectively controlled the hallucination rate among a range of examined characteristics.
CAA activation engineering requires specifying contrastive completions. A contrastive completion is a prompt composed with two completions: the first is the desired completion and the second is the undesired completion. However, (Jorgensen et al., 2023) achieved stronger sentiment shift by replacing the “mean activation vector on undesired completions” with the “mean activation vector on a related dataset.” Inspired by these activation addition approaches, BIDPO (Cao et al., 2024) used a contrastive variant of Direct Preference Optimization (Rafailov et al., 2024) to optimize a vector to produce the desired contrastive effects. BIDPO boosts Llama-2–7b-chat TruthfulQA MC1 by approximately 15%, while CAA only boosted MC1 by approximately 3%.
While activation engineering has enjoyed recent attention, the area has a rich history dating back to vision models and word2vec (Mikolov et al., 2013). For example, (Larsen et al., 2016; White et al., 2016) found a “smile vector” in a GAN. For more early work in steering image models with vector arithmetic, refer to e.g. (Upchurch et al., 2017; Reed et al., 2016; Wang et al., 2019; Goh et al., 2017). “Steering vector” was coined by (Subramani et al., 2022) who optimized a vector to force GPT-2 to output arbitrary output sequences.

(Li et al, 2023) demonstrated “inference-time intervention”, which adds a “truth vector” to a subset of truth-relevant attention heads at a layer (with relevance determined by linear probes (Alain & Bengio, 2016)). By doing so, they significantly boosted the informative-truthfulness score on the TruthfulQA dataset while preserving MMLU performance. (Turner et al., 2023) and (Li et al, 2023) concurrently demonstrated the feasibility of activation engineering in language models, inspiring a wealth of follow-up papers in the field of activation engineering.
(Arditi et al., 2024) created a “refusal vector” by computing the average activation difference between refusal and non-refusal responses. By adding or ablating the refusal vector, they could dramatically increase or decrease the refusal rate. (Stickland et al., 2024) derived a CAA steering vector and regularized the model to minimize the vector’s KL impact on a set of unrelated prompts. By averaging (Wortsman et al., 2022) these weights with the weights of a LORA-adapted model, (Stickland et al., 2024) further increased performance while minimizing performance impact on the model. (Price et al., 2024) trained backdoors which appear to trigger when the model infers it is processing headlines from some future date.
Given a trigger prompt, they claim to find “future” — “past” steering vectors which strongly control the activation of the backdoor. Adaptive activation steering (Wang et al., 2024) dynamically applies multiple truth-related steering vectors using linear probes. (Rahn et al., 2024) use combinations of steering vectors to increase the high-level uncertainty of LLM agents and improve their exploration properties.
Hallucinations
A wide range of complementary techniques can reduce hallucination rates in LLMs. The vast majority of these techniques are compatible with steering vectors. We will only cover a few here.
(Farquhar et al., 2024) detect certain kinds of hallucinations by checking the model for consistency across rephrasings or augmentations of the prompt. (Tian et al., 2023) use DPO and unsupervised factuality-correlated preference data augmentation to dramatically reduce hallucinations in Llama-1 and Llama-2 7B models. Contrastive decoding (Li et al., 2022) is an inference-time technique which amplifies predictive differences between a strong model and a weak model. DoLA (Chuang et al., 2023) amplifies differences in predictions between the final layer and an earlier layer.
(Zhang et al., 2024)’s TruthX approach recently achieved impressive gains on TruthfulQA for Llama-2–7b, boosting MC1 performance from 34.6% to 54.2%. While this ~20% gain is larger than BIDPO’s 15% gain on the same model, the TruthX approach is significantly more complicated. TruthX adds a steering vector in the latent space of an autoencoder trained to represent truth information. Two similar autoencoders are trained at each sublayer of the transformer, requiring (2 × n_layers) autoencoders, each with O(d_model²) learnable parameters, for a total of O(n_layers × d_model²) parameters. In comparison, LORAs require only O(n_layers × n_rank × d_model) parameters for n_rank ≪ d_model. Because of TruthX’s quadratic dependence on d_model, we compare BIDPO to LORAs only: we are interested in steering methods which are both economic and effective.
Parameter-efficient finetuning
Our finetuning baseline is LORA (Hu et al., 2021), which efficiently updates weight matrices by computing only low-rank adapters. Activation engineering inspired “representation finetuning” (ReFT) (Wu et al., 2024), which learns a task-specific subspace. Then a parameter update is optimized within that weight subspace, allowing highly sample-efficient learning. We do not compare to this approach.
