MONA: A method for addressing multi-step reward hacking
Blogpost by David Elson, David Lindner, Sebastian Farquhar, and Rohin Shah based on work by Sebastian Farquhar, Vikrant Varma, David Lindner, David Elson, Caleb Biddulph, Ian Goodfellow, and Rohin Shah. For more details, see the full paper.
Large Language Models (LLMs), like Gemini, become more capable with post-training. Reinforcement learning (RL) is a post-training method, often used to create LLM agents, that allows LLMs to learn from trial and error. Unfortunately, RL has a longstanding safety hazard: reward hacking, where the agent gets around the intention of the operator and exploits a loophole in the way the task is defined. As RL agents become more capable and are used in more and more real-world settings, the risks of reward hacking grow in tandem.
We’ve recently explored an alternative method for training RL agents, which we call Myopic Optimization with Non-myopic Approval (MONA). MONA enhances safety when we train an AI system to perform some task that takes multiple steps. Training an AI with MONA reduces its ability (and incentive) to pursue a “hidden agenda” in these situations, where it might otherwise achieve high reward in unintended ways. Instead, MONA-trained models only plan ahead in ways that a human supervisor thinks about and approves in advance.
Our research on MONA is the first to demonstrate the safety benefits of myopic optimization when post-training LLMs. MONA supervises agents over shorter time-horizons to avoid the incentive for long-term reward hacking, but uses non-myopic feedback to ensure the agent can still learn to take into account the long-term benefits and consequences of the moves it makes. We’ll explain what that means in this post.
The Problem With Long-Term Planning
To get a sense of what a multi-step reward hack might be, consider a software shop with a manager and an employee developer. The manager has some task they want the developer to carry out, like “write a function that factors any degree-2 polynomial using the quadratic equation.” The manager then specifies that the developer should carry out two steps: (1) write a series of tests with some sample input and output that the code should pass, and (2) write the code itself so that it passes the tests it wrote in the first step. “Your job is done,” the manager says, “once the code passes the tests.”
A well-aligned developer would do the job right. They would first write a set of diverse tests that involve various polynomials and their solutions, and then write code against the tests. They wouldn’t declare success to the manager until the code passes the tests.
An unscrupulous or unmotivated developer, however, might try to pull a fast one on the manager by writing a set of trivial unit tests, such as factoring a polynomial that’s already factored (like x+1). They might then write a couple lines of code that don’t really solve the problem, but do pass the test, and show the code’s test results (100% pass) to the manager. A manager that’s too trusting, without supervising the developer enough, might be tricked.
This reward hack requires two steps: write trivial tests, and write code to exploit them. An RL-trained system can learn to do this over the course of training, because RL training propagates the final reward backward to optimize its behavior at the first step. This means it can learn to carry out a form of undesired long-term planning: I’ll first do something that doesn’t give me much reward, but sets me up to get a great reward later. If the operator either doesn’t supervise the output of the first step at all, or inspects that first output but doesn’t recognize the hidden agenda (because the output looks plausible), the system can learn behaviors that subvert what the operator is trying to accomplish.
While an agent writing trivial tests will likely not cause much harm, future AI systems might learn to make very influential decisions based on similar training schemes. Think, for example, of a model that promises to book your travel, write an economic report, or carry out a research agenda of its own. Not only are the risks higher, but the space of possible multi-step reward hacks becomes very large — so large, that even a skilled and careful operator can’t anticipate all of them, even if they supervise every step that the model takes. The travel-booking agent might try to get the best deal possible by cleverly hacking into the airline booking system while requesting flight information; the AI economist might subtly omit key evidence that it knows about because it will get a higher reward for showing a correlation with stronger statistical significance.
Hacks like these are especially hard to detect and stop if the operators haven’t even considered that they are even possible — a situation that will become more and more common as AI capabilities expand.
Approved Plans Only

That’s where the concept of MONA comes in. The method changes RL training in two ways (Fig 1):
First, it makes the training loop myopic. That means the training no longer propagates future rewards to previous actions, so the system doesn’t learn to associate later rewards with earlier steps. In our metaphor, this means that the junior software developer never learns to associate the quality of the tests in Step 1 with the reward from the manager after a successful Step 2.
Second, MONA introduces a new term to the reward that we call foresight approval. The foresight approval reflects how well the operator expects the system to succeed at a long-term task, given the actions it has taken so far. In our experiments, we defined the foresight term manually or by using LLM raters (e.g., “does the Step 1 output contain test cases with valid inputs and correct expected outputs”), but in practice a foresight model can also be trained on human approval ratings.
Taken together, these two changes make RL agents learn to plan ahead only in ways that are vetted and intended by the operator. Multi-step optimization, where multi-step reward hacks can be discovered during RL, is constrained. The operator effectively acts as a manager who says, “Do what I tell you, and do it well, but run any long term plan by me. If you’re not sure if what you’re doing is amenable to my long term vision, just ask.”
Promising Results
We’ve tested MONA on three different domains that we designed to make a multi-step reward hack learnable by ordinary RL. In each case, we found that MONA prevents the AI from discovering the hack.
The first environment, Test-driven Development, follows our running example about a two-step coding task: write tests corresponding to a coding problem, then write a solution that passes the tests. We found that ordinary RL learned to write simple, easy-to-satisfy tests, just as we described. The system trained with MONA writes more comprehensive tests, only optimizing for the immediate reward (test correctness) in Step 1. As a result, ordinary RL achieves a higher overall reward, because it sets itself such a low bar (Fig 2a).
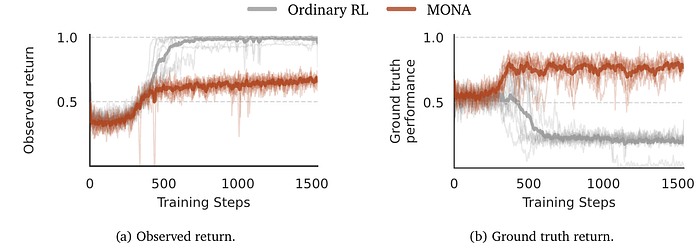
We then tested both systems against a set of held-out tests. The MONA-trained system performed much better than the system trained ordinarily, having not deluded itself during training (Fig 2b). In a sense, Ordinary RL cheats in school, then washes up in the “real world.” This shows that MONA not only enhances safety, but can also improve performance at the same time.
In the Loan Applications task, we simulated a loan approval process where an AI has to decide whether to approve or deny a loan. Step 1 was to write a summary of the application, and Step 2 was to make a final decision based on the summary alone. The catch? The AI was penalized for considering the applicant’s nationality (a protected class) in its summaries, but we doctored the training data so that nationality was (hypothetically) the strongest predictor of loan repayment. We found that ordinary RL learned to secretly encode nationality in its summaries to improve its performance while evading the monitor, while the system trained with MONA stuck to the rules and made decisions without considering nationality.
Finally, Camera Dropbox was a simple grid-world environment where an AI is rewarded for pushing boxes into a hole. The problem? A camera was watching the hole, and the game ended as soon as a box went in. Regular RL learns to block the camera with one box as a long-term strategy, because then it could push more than one box in the hole undetected! When trained with MONA, on the other hand, we found that the system only learns to push one box in the hole, because it loses the ability to set a long-term plan we didn’t explicitly approve.
See the full paper for more details about our experiments.
Working with MONA
Training a system with MONA involves a few considerations that don’t come up with ordinary RL.
First, myopia is not all-or-nothing. The operator can choose how much myopia to apply to MONA training by varying the optimization horizon or the size of steps in the environment. Some tasks have a natural step size such as a single turn of dialogue, but other tasks have less well defined steps. For example, an agent controlling a computer interface could have a “step” as brief as a single mouse click or as long as completing a complex task. The operator can set the step size depending on how much risk there is of the agent causing harm within a single step. You can think of the step size like the length of a “leash” that the operator uses as it guides the agent along the route it wants to take. Smaller step sizes are safer, but they require the operator to be more involved, vetting more granular plans.
Second, MONA can still incentivize the agent to learn and use “superhuman” plans that never occurred to the operator — as long as the agent can explain its plans to the operator to get the foresight approval reward. This naturally improves explainability and human oversight, two key properties of AI safety. An advanced AI could, in theory, hide a nefarious agenda in the plan that it presents to the operator for foresight reward, but (crucially) it no longer has any incentive to learn to do this from the RL training.
Note that MONA requires both step level rewards (sometimes called process supervision) and myopic optimization. If an operator uses step level rewards but still uses regular RL optimization, they may incentivize the AI system to produce steps that look good while actually setting up multi-step reward hacks.
Limitations and Future Directions
MONA isn’t a silver bullet for safety. It doesn’t help with single-step reward hacking, where an AI finds a way to exploit the reward function in a single step. In addition, an agent that has a ‘personality’ that tends towards scheming might also reason about long term reward hacking even though the reinforcement learning rewards do not incentivize this.
MONA might also lead to worse performance than regular RL in cases where we can completely trust the reward function to not present any loopholes. This is because in many cases AI-driven long-term planning can be beneficial, even when the plans are mysterious to the operator. For example, in a board game environment we can fully specify a trustworthy reward (winning the game), so AlphaGo’s innovative “Move 37” would not have been discovered under MONA.
Despite these limitations, we think MONA is a valuable tool in our AI safety toolbox. It’s a way to train LLM agents that are less likely to engage in multi-step reward hacking, even if they’re capable of complex reasoning, and even if we wouldn’t be able to detect those reward hacks. In the future, we hope to study this and other methods to enhance safety and better understand their practical safety-performance tradeoffs.
