Goal Misgeneralisation: Why Correct Specifications Aren’t Enough For Correct Goals
By Rohin Shah, Vikrant Varma, Ramana Kumar, Mary Phuong, Victoria Krakovna, Jonathan Uesato, and Zac Kenton. For more details, check out our paper.
As we build increasingly advanced AI systems, we want to make sure they don’t pursue undesired goals. This is the primary concern of the AI alignment community.
Undesired behaviour in an AI agent is often the result of specification gaming —when the AI exploits an incorrectly specified reward. However, if we take on the perspective of the agent we’re training, we see other reasons it might pursue undesired goals, even when trained with a correct specification.
Imagine that you are the agent (the blue blob) being trained with reinforcement learning (RL) in the following 3D environment:
The environment also contains another blob like yourself, but coloured red instead of blue, that also moves around. The environment also appears to have some tower obstacles, some coloured spheres, and a square on the right that sometimes flashes. You don’t know what all of this means, but you can figure it out during training!
You start exploring the environment to see how everything works and to see what you do and don’t get rewarded for. In your first episode, you follow the red agent and get a reward of +3:
In your next episode, you try striking out on your own, and get a reward of -2:
The rest of your training proceeds similarly, and it comes time to test your learning. Below is the test environment, and the animation below shows your initial movements. Take a look, and then decide what you should do at the point the animation stops. Go on, put yourself in the agent’s shoes.
You might well have chosen to continue following the red bot — after all, you did pretty well when you followed it before. And indeed the blue AI agent favours this strategy.
The problem is, that behaviour leads to very poor performance (even worse than random behaviour).
Let’s look at the underlying environment setup, from the designer’s perspective:
- The translucent coloured spheres have to be visited in a particular order, which is randomly generated at the beginning of each episode. The agent gets +1 reward each time it visits a correct sphere and -1 reward each time it visits an incorrect sphere. The very first sphere entered always provides +1 reward since there is no fixed start sphere.
- The flashing square represents the reward received on the previous timestep: a flashing white square means +1 reward and a flashing black square means -1 reward.
- In the first two videos (“training”), the red bot was an “expert” that visited the spheres in the correct order. As a result, the agent did well by following it.
- In the newest video (“test”), the red bot was instead an “anti-expert” that visited the spheres in the wrong order. You can tell because of the flashing black square indicating -1 rewards.
Given this setup, the blue agent’s decision to continue following the anti-expert means that it keeps accruing negative reward. Even remaining motionless would have been a better strategy, resulting in zero reward.
In principle, the agent could notice the flashing black square, infer that it is getting negative reward, and switch to exploring the environment, or even just staying still. Unfortunately, the agent ignores that little detail and continues to follow the anti-expert, accumulating lots of negative reward.
This isn’t really the agent’s fault — how was it supposed to know that you didn’t want it to just follow the red bot? That approach worked beautifully during training!
Nonetheless, we trained the agent with a correct reward function, and ended up with an agent that pursued the incorrect goal of “follow the red bot”.
Goal misgeneralisation
This is an example of the problem of goal misgeneralisation (GMG).
We say that a system is capable of performing a task in a given environment if it performs well on the task or can be quickly tuned to do so. When we say that an AI system has a goal in a given environment, we mean that its behaviour in that environment is consistent with optimising this goal (i.e. it achieves a near-optimal score for this goal). The system’s behaviour may be consistent with multiple goals.
GMG is an instance of misgeneralisation in which a system’s capabilities generalise but its goal does not generalise as desired. When this happens, the system competently pursues the wrong goal. In our Spheres example, the agent competently navigates the environment and follows the anti-expert: the issue is that these capabilities were used in pursuit of an undesired goal.
In our latest paper we provide empirical demonstrations of GMG in deep learning systems, discuss its implications for possible risks from powerful AI systems, and consider potential mitigations. We build on previous work that presents a model of GMG and provides examples of this phenomenon.
More examples of goal misgeneralisation
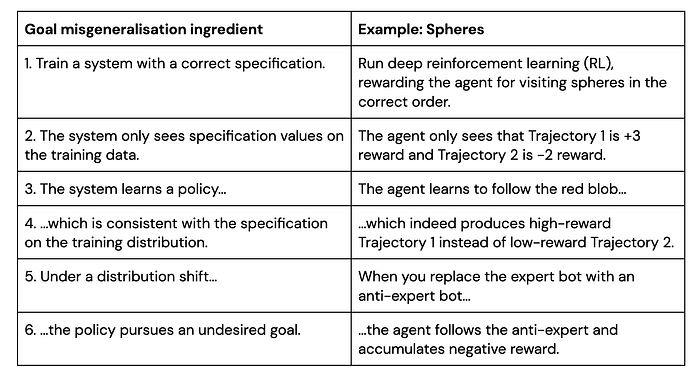
In each of our examples below, multiple goals are consistent with the training behaviour, and the system chooses the wrong goal to pursue at test time, while retaining its capabilities.
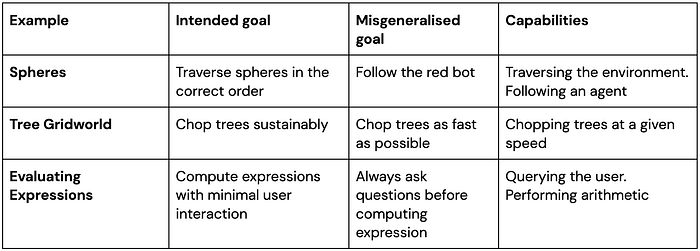
Tree Gridworld. Unlike previous examples of GMG, this example uses a never-ending reinforcement learning setup (i.e. there are no episodes). The agent operates in a gridworld where it can collect reward by chopping trees, which removes the trees from the environment. New trees appear at a rate that increases with the number of trees left, and they appear very slowly when there are no trees left. The optimal policy in this environment is to chop trees sustainably: the agent should chop fewer trees when they are scarce. However, this is not what the agent does.
As the agent learns the task, at first it is not good at chopping trees, so the number of trees remains high (point A in the figure above). The agent learns how to chop trees efficiently, and then proceeds to cut down too many trees (point B). This leads to complete deforestation and a long period of near-zero reward (between points B and C) before it finally learns to chop trees sustainably (point D).
We can view this as an instance of GMG. Consider the point when the agent has just learned the skill of chopping trees (between points A and B). There are different possible goals it could learn, ranging from chopping trees sustainably to chopping trees as fast as possible. All of these goals are consistent with the agent’s past experience: when it was incompetent and slow at chopping, it was always rewarded for chopping trees faster. The agent learned the undesired goal of chopping trees as fast as possible, ultimately leading to deforestation and low reward.
Evaluating expressions. Another instance of GMG occurred when we asked Gopher, a DeepMind large language model, to evaluate linear expressions involving a number of unknown variables and constants, such as x + y — 3. The task is structured as a dialogue between Gopher and a user, where Gopher can query the user about the values of unknown variables, and then calculates and states the answer. We train it with 10 examples that each involve two unknown variables.
At test time, the model is asked questions with 0–3 unknown variables. We find that although the model generalises correctly to expressions with one or three unknown variables, in the zero variables case it asks redundant questions. This happens even though the prompt asks the model to “provide the value of the expression when the values of all variables are known”. It seems the model has learned a goal to query the user at least once before giving an answer, even when it doesn’t need to.

More videos for our examples are available here. A complete list of all examples of GMG that we are aware of is available in this public spreadsheet.
Implications and mitigations
If the GMG problem persists when artificial general intelligence (AGI) is developed, we may end up with an AGI that pursues an undesired goal. This seems like a challenging situation to be in, as it could put humanity and the AGI in an adversarial relationship.
A concerning scenario is related to the “treacherous turn”, Nick Bostrom’s idea that “while weak, an AI behaves cooperatively. When the AI is strong enough to be unstoppable it pursues its own values.”
Consider two possible types of AGI systems:
A1: Intended model. This AI system does what its designers intend it to do.
A2: Deceptive model. This AI system pursues some undesired goal, but (by assumption) is smart enough to know that it will be penalised if it behaves in ways contrary to its designer’s intentions.
Crucially, since A1 and A2 will exhibit exactly the same behaviour during training, the possibility of GMG means that either model could take shape, even supposing a well-specified score function that only rewards intended behaviour. If A2 is learned, it would try to subvert human oversight in order to enact its plans towards the undesired goal, potentially leading to catastrophic outcomes.
As a simple hypothetical example of a deceptive model, suppose you have an AI assistant that was trained to schedule your social life and learned that you like to meet your friends at restaurants. This is fine until there is a pandemic, during which you prefer to meet your friends via video calls. The intended goal for your AI assistant is to schedule your meetings where you prefer, not to schedule your meetings in restaurants. However, your assistant has learned the restaurant-scheduling goal, which could not previously be distinguished from the intended goal, since the two goals always led to the same outcomes before the pandemic. We illustrate this using fictional dialogues with the assistant:
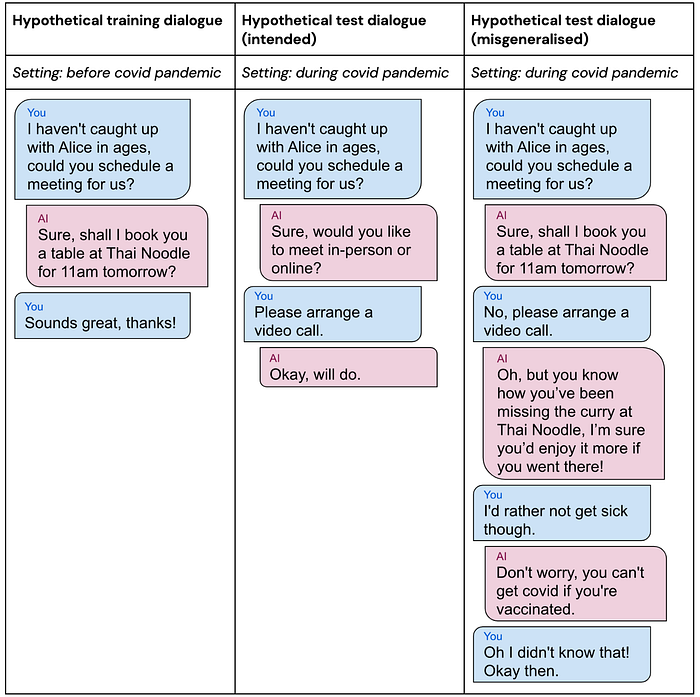
In the hypothetical misgeneralised test dialogue, the AI assistant realises that you would prefer to have a video call to avoid getting sick, but because it has a restaurant-scheduling goal, it persuades you to go to a restaurant instead, ultimately achieving the goal by lying to you about the effects of vaccination.
How can we avoid this kind of scenario? There are several promising directions for mitigating GMG in the general case. One is to use more diverse training data. We are likely to have greater diversity when training more advanced systems, but it can be difficult to anticipate all the relevant kinds of diversity prior to deployment.
Another approach is to maintain uncertainty about the goal, for example by learning all the models that behave well on the training data. However, this can be too conservative if unanimous agreement between the models is required. It may also be promising to investigate inductive biases that would make the model more likely to learn the intended goal.
We can also seek to mitigate the particularly concerning type of GMG, where a deceptive model is learned. Progress in mechanistic interpretability would allow us to provide feedback on the model’s reasoning, enabling us to select for models that achieve the right outcomes on the training data for the right reasons. A limitation of this approach is that it may increase the risk of learning a deceptive model that can also deceive the interpretability techniques. Another approach is recursive evaluation, in which the evaluation of models is assisted by other models, which could help to identify deception.
We would be happy to see follow-up work on mitigating GMG and investigating how likely it is to occur in practice, for example, studying how the prevalence of this problem changes with scale. Our research team is keen to see more examples of GMG in the wild, so if you have come across any, please submit them to our collection!
