DeepMind Safety Research




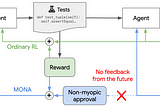
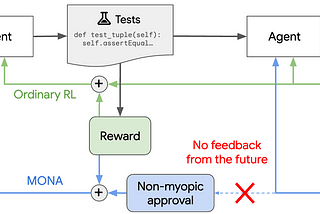

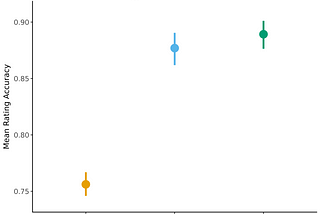
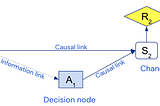





DeepMind Safety Research
We research and build safe AI systems that learn how to solve problems and advance scientific discovery for all. Explore our work: deepmind.google
We research and build safe AI systems that learn how to solve problems and advance scientific discovery for all. Explore our work: deepmind.google